Adding an NFS Data Sink
WARNING: NFS support for both External Storage and Data Sinks will be deprecated in a future release of Stellar Cyber. Stellar Cyber advises you not to use this feature and instead choose a cloud-based option. If cloud-based options are not possible, reach out to Stellar Cyber Customer Success to discuss on-premises options compatible with the AWS S3 API.
You must have Root scope to use this feature.
You can add an NFS Data Sink from the System | Data Processor | Data Sinks page using the instructions in this topic. Adding an NFS Data Sink consists of the following major steps:
- Create an NFS storage location and take note of its hostname, port number, and storage directory path.
- Add the NFS Data Sink in Stellar Cyber.
Creating an NFS Storage Location
Stellar Cyber supports NFSv3 and NFSv4. When you configure an NFS external storage location you must set the following permissions:
-
rw—Allow both read and write requests on this NFS volume. -
no_subtree_check—Disables subtree checking, which has mild security implications, but can improve reliability. -
insecure—Allows clients with NFS implementations that don't use a reserved port for NFS. -
no_root_squash—Disables the default behavior of squashing the root user.
You need the following information about your NFS storage when adding it as a Data Sink in Stellar Cyber:
- hostname or IP address of the server
- port number (2049 is the default)
- complete path to the NFS server directory where you want to sink data
Stellar Cyber does NOT support NFS storage in MS-Windows environments.
Adding the NFS Data Sink in Stellar Cyber
To add an NFS Data Sink:
- Click System | Data Processor | Data Sinks. The Data Sink list appears.
-
Click Create. The Setup Data Sink screen appears.
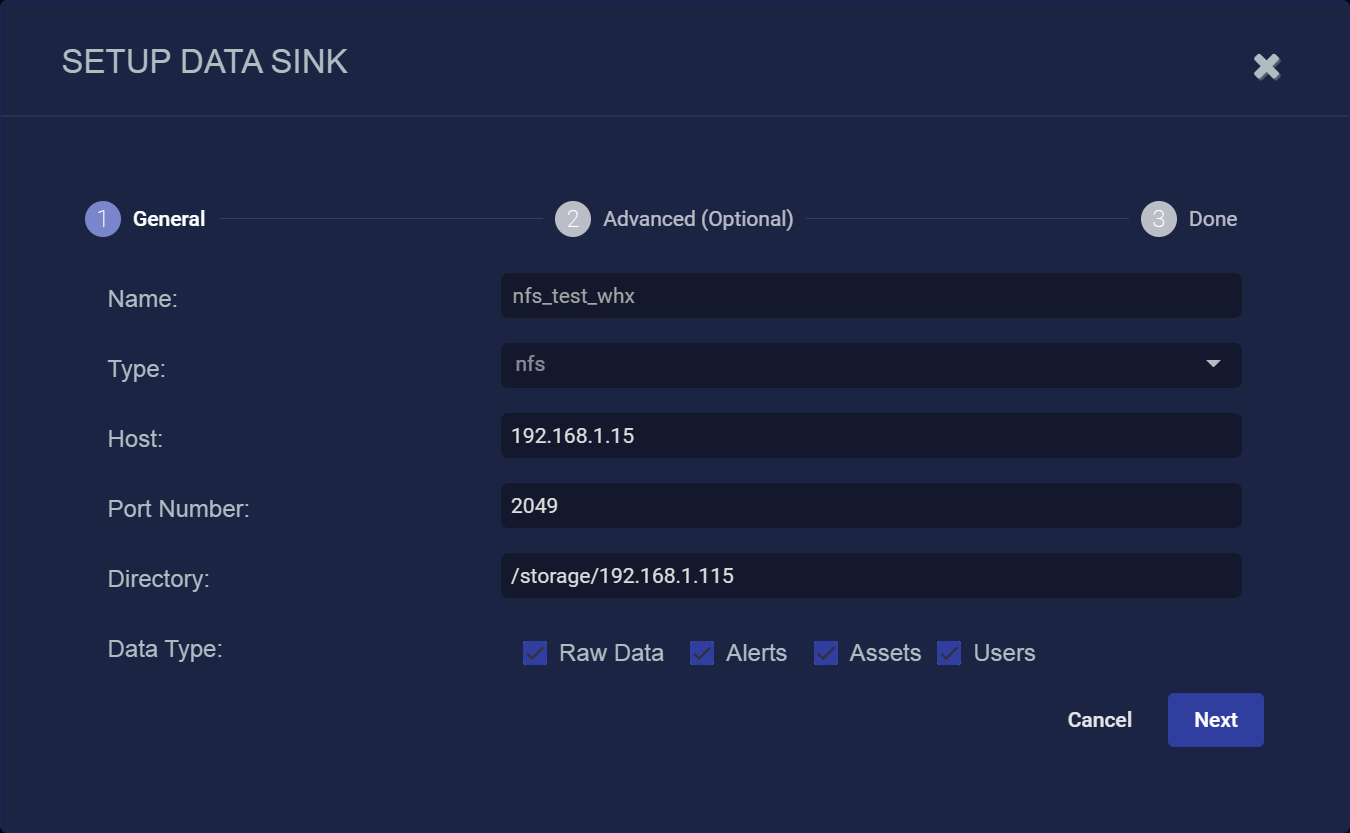
- Enter the Name of your new Data Sink. This field does not support multibyte characters.
-
Choose NFS for the Type.
Additional fields appear in the Setup Data Sink screen:
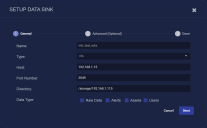
- Enter the FQDN or IP address of the NFS server in the Host field.
-
Enter the Port on the NFS server. The default is 2049.
-
Enter the Directory. This is the path where you wan tto sink data on the NFS server. Note that this field does not accept URLs.
-
Select the types of data to send to the Data Sink by toggling the following checkboxes:
-
Raw Data – Raw data received from sensors, log analysis, and connectors after normalization and enrichment has occurred and before the data is stored in the Data Lake.
-
Alerts – Security anomalies identified by Stellar Cyber using machine learning and third-party threat-intelligence feeds, reported in the Alerts interface, and stored in the aella-ser-* index.
-
Assets – MAC addresses, IP addresses, and routers identified by Stellar Cyber based on network traffic, log analysis, and imported asset feeds and stored in the aella-assets-* index.
-
Users – Users identified by Stellar based on network traffic and log analysis and stored in the aella-users-* index.
Alerts, assets, and users are also known as derived data because Stellar Cyber extrapolates them from raw data.
In order to import data from an NFS data sink, you must check at least one of the Alerts, Assets, or Users options.
-
-
Click Next.
The Advanced (Optional) page appears.
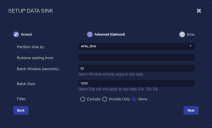
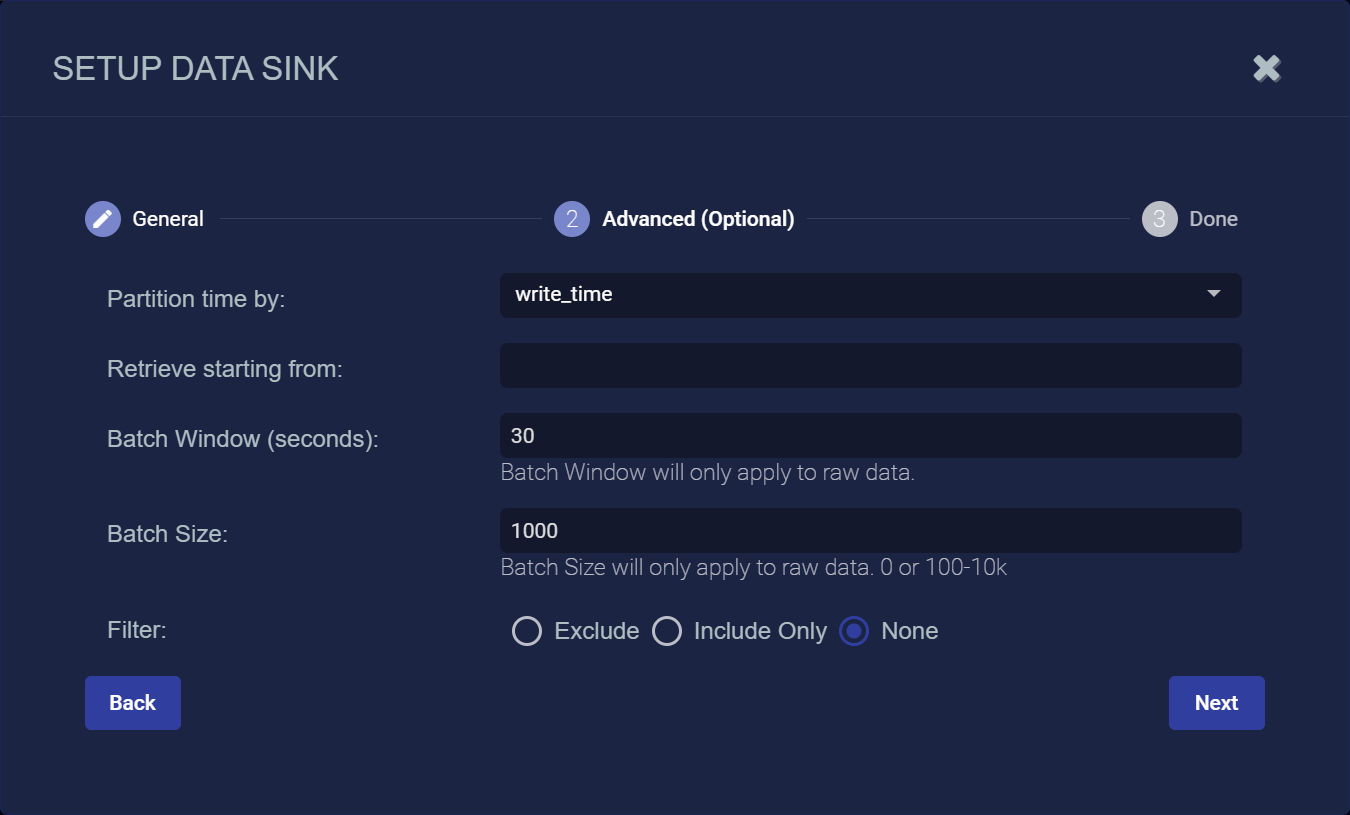
-
Specify whether to partition records into files based on their write_time (the default) or timestamp.
Every interflow record includes both of these fields:
-
write_time indicates the time at which the Interflow record was actually created.
-
timestamp indicates the time at which the action documented by the Interflow record took place (for example, the start of a session, the time of an update, and so on).
When files are written to the Data Sink they are stored at a path like the following, with separate files for each minute:

In this example, we see the path for November 9, 2021 at 00:23. The records appearing in this file would be different depending on the setting of the Partition time by setting as follows:
-
If write_time is enabled, then all records stored under this path would have a write_time value falling into the minute of UTC 2021.11.09 - 00:23.
-
If timestamp is enabled, then all records stored under this path would have a timestamp value falling into the minute of UTC 2021.11.09 - 00:23.
In most cases, you will want to use the default of write_time. It tends to result in a more cost-efficient use of resources and is also compatible with future use cases of data backups and cold storage using a data sink as a target.
-
-
You can use the Retrieve starting from field to specify a date and time from which Stellar Cyber should attempt to write alert, asset, and user records to a newly created Data Sink. You can click in the field to use a handy calendar to set the time/date
Note the following:
-
If you do not set this option, Stellar Cyber simply writes data from the time at which the sink is created.
-
This option only affects alert, asset, and user records. Raw data is written from the time at which the sink is created regardless of the time/date specified here.
-
If you set a time/date earlier than available data, Stellar Cyber silently skips the time without any available records.
-
-
Use the Batch Window (seconds) and Batch Size fields to specify how data is written to the sink.
-
The Batch Window specifies the maximum amount of time that can elapse before data is written to the Data Sink.
-
The Batch Size specifies the maximum number of records that can accumulate before they are sent to the Data Sink. You can specify either 0 (disabled) or a number of records between 100 and 10,000.
Stellar Cyber batches data to the Data Sink depending on whichever of these parameters is reached first.
So, for example, consider a Data Sink with a Batch Window of 30 seconds and a Batch Size of 300 records:
-
If at the end of the Batch Window of 30 seconds, Stellar Cyber has 125 records, it sends them to the data sink. The Batch Window was reached before the Batch Size.
-
If at the end of 10 seconds, Stellar Cyber has 300 records, it send the 300 records to the Data Sink. The Batch Size was reached before the Batch Window.
These options are primarily useful for data sink types that charge you by the API call (for example, AWS S3 and Azure). Instead of sending records as they are received, you can use these options to batch the records, minimizing both API calls and their associated costs for Data Sinks in the public cloud.
By default, these options are set to 30 seconds and 1000 records for NFS data sinks.
-
-
You can use the Filter options to Exclude or Include specific Message Classes for the Data Sink. By default, Filter is set to None. If you check either Exclude or Include, an additional Message Class field appears where you can specify the message classes to use as part of the filter. For example:

You can find the available message classes to use as filters by searching your Interflow in the Investigate | Threat Hunting | Interflow Search page. Search for the msg_class field in any index to see the prominent message classes in your data.
-
Click Next to review the Data Sink configuration. Use the Back button to correct any errors you notice. When you are satisfied with the sink's configuration, click Submit to add it to the DP.
- Click Submit.
The Compression option does not appear for NFS Data Sinks because compression is always used for this sink type.

The new Data Sink is added to the list.
NFS Data Sink Modes 
By default, Stellar Cyberwrites data to an NFS data sink in plain mode. In plain mode, each tenant on the DP generates at least one file every minute for each enabled data type and task thread.
This works well for most data sink scenarios. However, in situations where the DP has many tenants with sparse data patterns, plain mode can result in the transfer of many small files to the data sink. NFS (especially v4) does not handle multiple small files efficiently, so situations can arise where the data sink can not keep up with the ingestion speed.
In situations such as this, you can enable tar mode on the DP. When tar mode is enabled, the DP creates a tarball of data to send to the NFS data sink every 10 minutes. Once the data arrives at the NFS data sink, a background process provided by Stellar Cyber cyber extracts the tarball and stores the data in the same format and structure as it would have been had plain mode been used.
You set up tar mode as follows:
-
Start by locating the /opt/aelladata/cluster-manager/scripts/nfs_sink_tar_extraction.sh script on the DP and copying it to the base directory of your NFS data sink. You can find the base directory for your NFS sink in the Data Sink Configuration page.
-
Run the nfs_sink_tar_extraction.sh script. For example:
sudo ./nfs_sink_tar_extraction.shOnce the nfs_sink_tar_extraction.sh script is running, it stays active in the background, waiting for tarballs to arrive every 10 minutes from the DP.
By default, nfs_sink_tar_extraction.sh uses the directory from which it as run as the input directory (which is why you copy it to the base directory of your data sink). You can use additional arguments to configure a different input directory and output log location.
-
Access the console for the DP and log in.
- Use the following command to enable tar mode:
set mode nfs_data_sink tarOnce tar mode is enabled, the DP sends a tarball to the NFS data sink every 10 minutes, storing it under the root directory of the NFS mount point (for example, /opt/aelladata/run/datasink/nfs/<sink-name>). In turn, the nfs_sink_tar_extraction.sh script you ran at the start of the procedure ensures that the tarball is extracted and its contents written to the standard format and structure for the data sink. The end result for sunk data is the same regardless of whether plain or tar mode is used. The difference is in how the data is sent and which approach makes the most efficient use of NFS for your deployment.
If at some point you want to return to plain mode, you can use the following command in the DP CLI:
set mode nfs_data_sink plain
Tips for Managing NFS Storage
Keep in mind that Stellar Cyber does not prevent your target NFS storage to keep it from filling up. Depending on the quantity of storage you have allotted, you may want to set up a cron job to purge older data periodically to prevent the partition from filling up. In addition, Stellar Cyber recommends that you create a notification rule in the System Action Center that alerts you when NFS storage is nearly filled up.
